DeepSeek v4: Arquitectura MoE de 1.6T e independencia de NVIDIA
DeepSeek v4 es un modelo Mixture-of-Experts (MoE) con 1.6 trillones de parámetros que busca competir directamente con GPT-5 y Claude 4.5 Opus (Dossier UsedBy). Su propuesta de valor se centra en ofrec

El Pitch
DeepSeek v4 es un modelo Mixture-of-Experts (MoE) con 1.6 trillones de parámetros que busca competir directamente con GPT-5 y Claude 4.5 Opus (Dossier UsedBy). Su propuesta de valor se centra en ofrecer rendimiento de nivel frontera con un coste cinco veces menor, eliminando por completo la dependencia del stack de NVIDIA al ejecutarse sobre hardware de Huawei.
Bajo el capó
DeepSeek v4 opera bajo una estructura MoE donde solo 49B de parámetros están activos por cada token generado, lo que explica su eficiencia en inferencia (LLM Stats, abril 2026). El modelo soporta una ventana de contexto de 1M de tokens e incluye un "Thinking Mode" con kernels deterministas a temperatura cero para tareas lógicas (API Docs).
Lo que funciona:
- El coste es imbatible: $1.74 por cada 1M de tokens en el tier Pro, casi una cuarta parte del precio de Claude 4.5 Opus (TrendingTopics.eu).
- En tareas de programación y matemáticas, mantiene un rendimiento de élite verificado internamente con un ~80% en SWE-bench (GitHub).
- La licencia es permisiva (MIT/Apache 2.0), lo que facilita su integración en entornos de desarrollo abiertos (GitHub repo bailaiOWO/DeepSeek-V4).
Lo que falla:
- La migración al ecosistema CANN de Huawei ha introducido bugs de continuidad en el estado de razonamiento, provocando errores 400 en sesiones multi-turno (GitHub Issue #3782).
- Existe un problema de "contaminación de identidad" donde el modelo, bajo presión, afirma ser GPT-4 (Dossier UsedBy).
- La eficiencia de los chips Huawei Ascend 950PR se queda en el 91% respecto a la paridad con NVIDIA A100, limitando su escalabilidad en picos de carga (Reddit/r/LocalLLaMA).
- El riesgo reputacional persiste debido a bloqueos previos por razones de seguridad nacional en Taiwán (The Hacker News 2025).
Lo que aún no sabemos:
- Falta una verificación independiente de su puntuación en SWE-bench, ya que hasta ahora son datos autoreportados.
- No hay claridad sobre si el entrenamiento se completó íntegramente en chips Huawei o si se utilizaron clusters "gris" de NVIDIA H20 (Dossier UsedBy).
La opinión de Ruben
Mi veredicto es que solo deberías usar DeepSeek v4 en producción para tareas de optimización de costes donde el fallo de un turno de razonamiento no sea catastrófico. Mi última configuración basada exclusivamente en CANN generó más calor en mi servidor que tokens válidos, así que cuidado con la infraestructura. Es una herramienta brillante para ahorrar presupuesto en side-projects de procesamiento masivo, pero la inestabilidad de sus kernels deterministas me impide recomendarlo como el LLM principal para una arquitectura empresarial crítica en este momento de 2026.
Actualmente rastreamos a 23 empresas en nuestra base que están utilizando esta herramienta, principalmente en el segmento de eficiencia de costes.
Código limpio siempre,
Ruben.
Diego Navarro - Early Adopter Tech Analyst at UsedBy.ai
Artículos relacionados
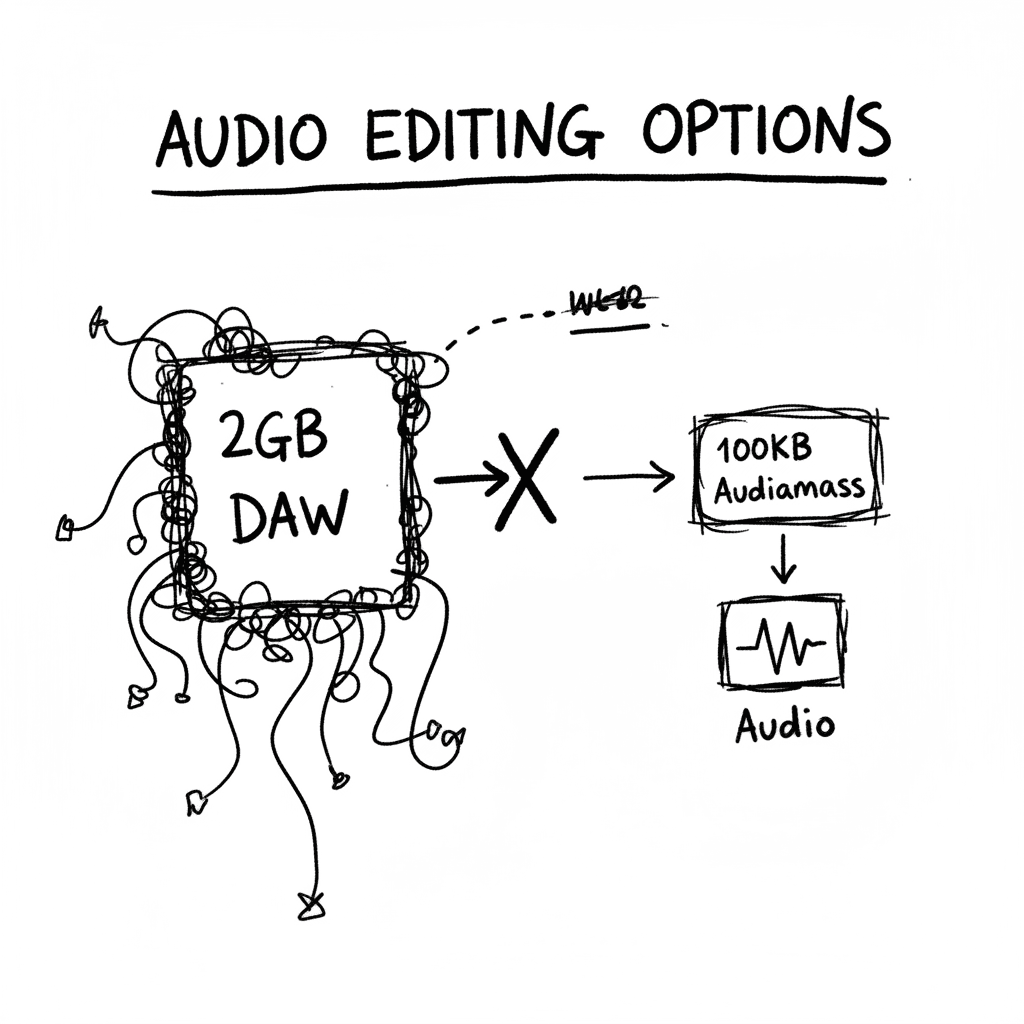
Audiomass: Edición de audio multitrack en 100KB de vanilla JS
Audiomass es un editor de audio basado en web que prescinde de backend y plugins, ejecutándose totalmente en el cliente mediante Web Audio API. En un 2026 saturado de aplicaciones pesadas, esta utilid
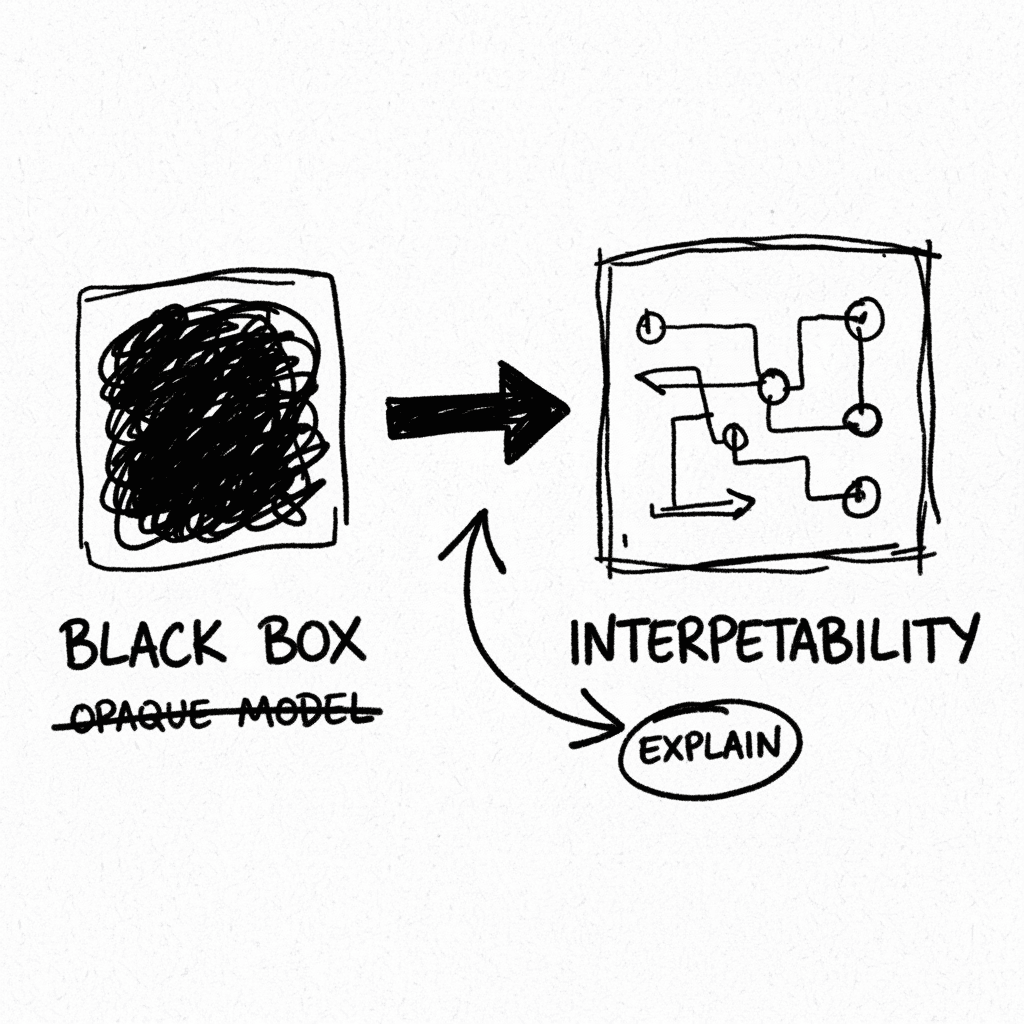
Protocolo Ético Magnifica Humanitas: La Interpretabilidad Mecanicista como Imperativo Moral
El documento establece que la tecnología nunca es neutral y que los ingenieros cargan con una responsabilidad directa sobre el impacto de sus arquitecturas. Basándose en la participación de figuras cl
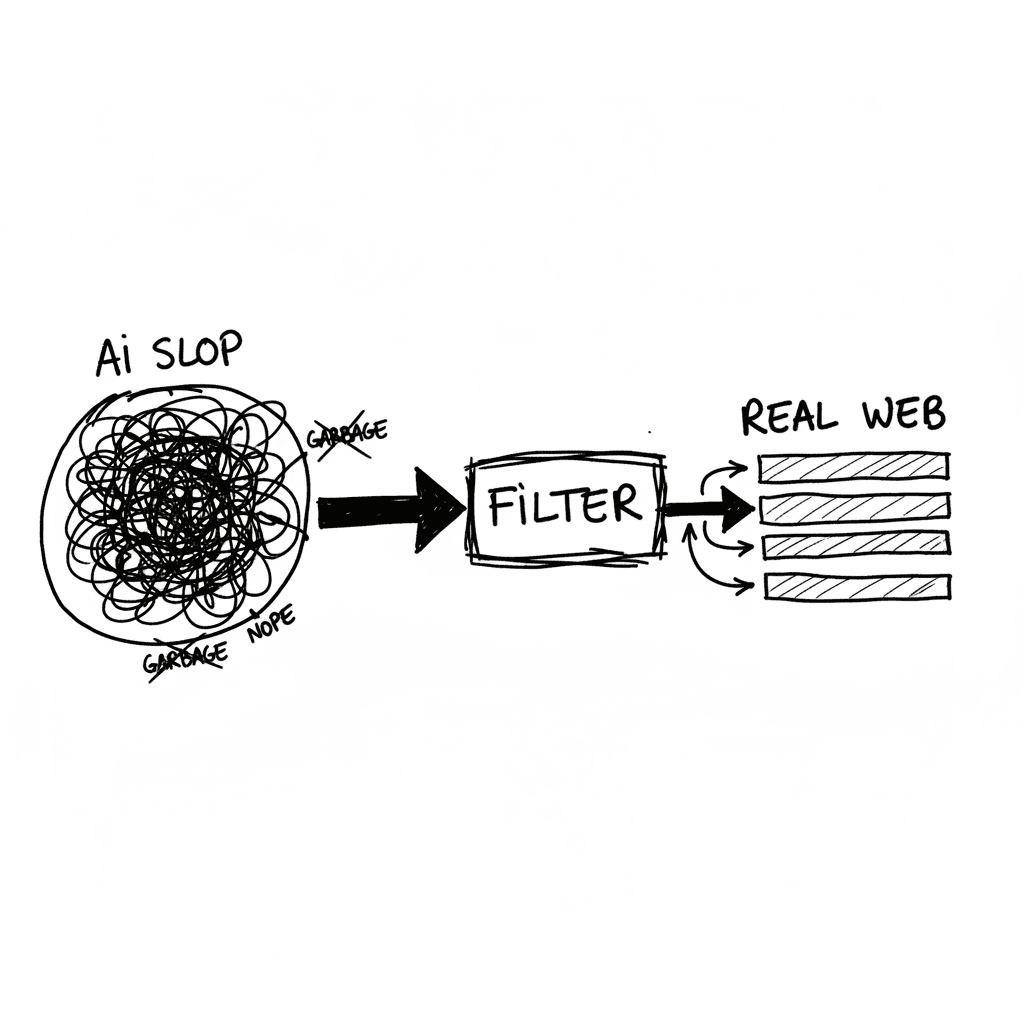
El estado de la búsqueda web en 2026: Kagi, Uruky y el modelo de suscripción
Google ha consolidado su transición de buscador a motor de respuestas con Gemini 3.5, capturando el 60% de las consultas sin que el usuario haga un solo clic (fuente: The Next Web). Ante este panorama
Mantente al día con las tendencias de adopción de IA
Recibe nuestros últimos informes y análisis en tu correo. Sin spam, solo datos.