TinyLoRA y la activación de razonamiento con 13 parámetros
Meta FAIR ha demostrado que es posible alcanzar un 91% de precisión en el benchmark GSM8K entrenando solo 13 parámetros, el equivalente a unos 26 bytes (arXiv:2602.04118). La propuesta asume que el ra

El Pitch
Meta FAIR ha demostrado que es posible alcanzar un 91% de precisión en el benchmark GSM8K entrenando solo 13 parámetros, el equivalente a unos 26 bytes (arXiv:2602.04118). La propuesta asume que el razonamiento es una capacidad latente en los LLM que solo requiere un "micro-update" para manifestarse.
Bajo el capó
La arquitectura utiliza una técnica de weight tying y tensores aleatorios fijos para proyectar vectores diminutos en actualizaciones completas de los pesos del modelo (GitHub). En pruebas con backbones Llama-3-8B y Qwen2.5-7B, el rendimiento en tareas de razonamiento subió un 15% con apenas una fracción del cómputo habitual (Dossier UsedBy).
Sin embargo, la cifra de 13 parámetros tiene letra pequeña: solo es efectiva para benchmarks básicos como GSM8K. Para desafíos de razonamiento complejo como AIME o MATH500, los autores admiten que se necesitan unos 200 parámetros para retener el 87% del rendimiento de un fine-tuning completo (arXiv:2602.04118).
Un punto crítico es que esta eficiencia depende exclusivamente de Reinforcement Learning (RL), específicamente mediante el algoritmo GRPO. El ajuste supervisado tradicional (SFT) falla estrepitosamente a esta escala, requiriendo entre 100 y 1000 veces más parámetros para obtener resultados similares (Dossier UsedBy).
Existen riesgos técnicos importantes identificados por la comunidad:
- Los kernels de inferencia actuales no soportan nativamente las capas de proyección aleatoria necesarias (Substack/The Kaitchup).
- Hay sospechas de saturación por filtración de datos en los benchmarks de las familias Qwen y Llama que podrían inflar los resultados (HN).
- La alta "programabilidad" del método permite crear micro-parches sigilosos para que actores maliciosos evadan filtros de seguridad (NeuroTechnus).
Aún no sabemos cómo generaliza esta técnica en tareas ajenas a las matemáticas, como la planificación estratégica o la escritura creativa. Tampoco disponemos de benchmarks que comparen este método aplicado sobre la escala de modelos como GPT-5 o Gemini 2.5 (Dossier UsedBy).
La opinión de Diego
TinyLoRA es una prueba de concepto brillante pero no es apta para producción hoy, 1 de abril de 2026. La dependencia de GRPO y la inestabilidad de sus kernels personalizados la relegan a ser una herramienta de experimentación para side-projects. Si necesitas mejorar el razonamiento de tus agentes en un entorno real, sigue usando el fine-tuning convencional en Claude 4 Sonnet; no arriesgues la integridad de tu sistema con micro-parches de 26 bytes que todavía no sabemos cómo escalan en entornos no matemáticos.
Código limpio siempre,
Diego.
Diego Navarro - Early Adopter Tech Analyst at UsedBy.ai
Artículos relacionados
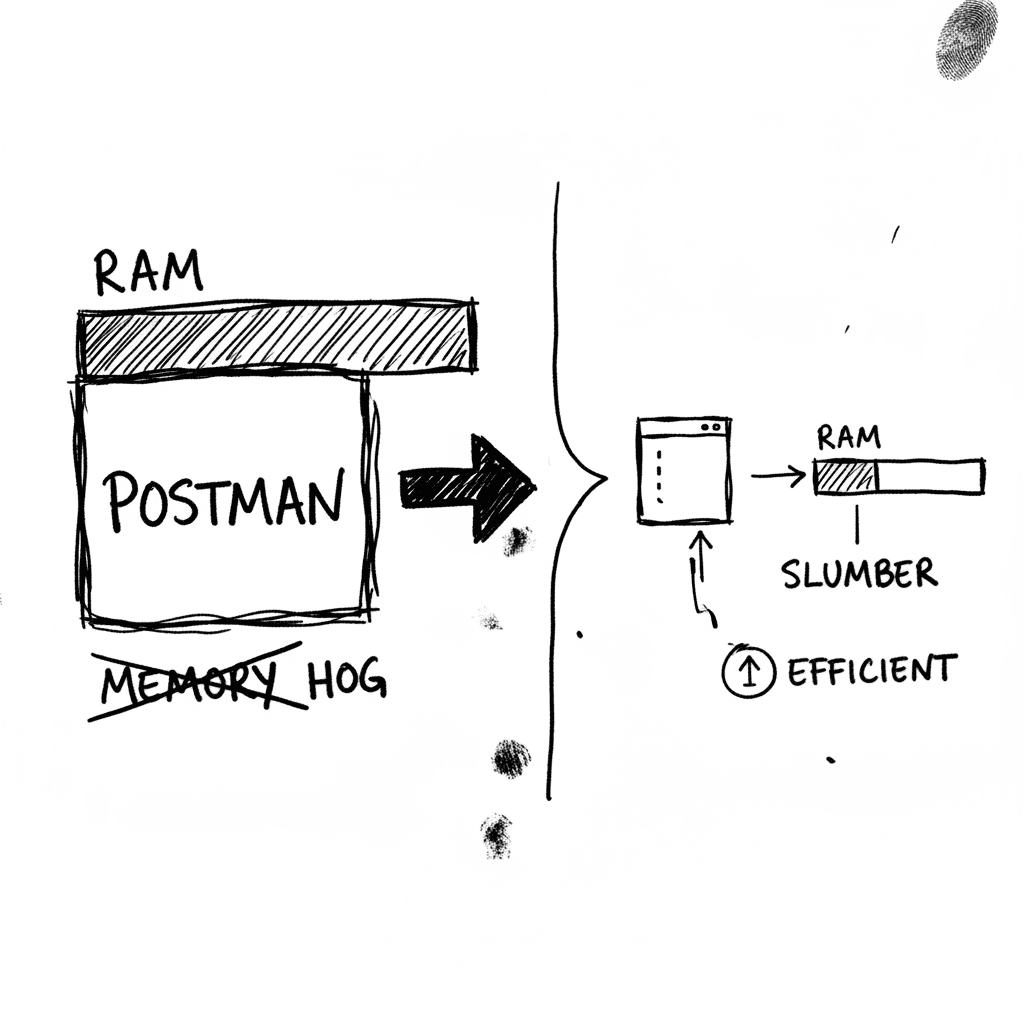
Slumber: gestión de APIs local-first vía terminal
Slumber es un cliente HTTP basado en terminal (TUI) escrito en Rust que utiliza archivos YAML para definir colecciones de peticiones sin depender de nubes externas (GitHub: lucaspickering/slumber). Es
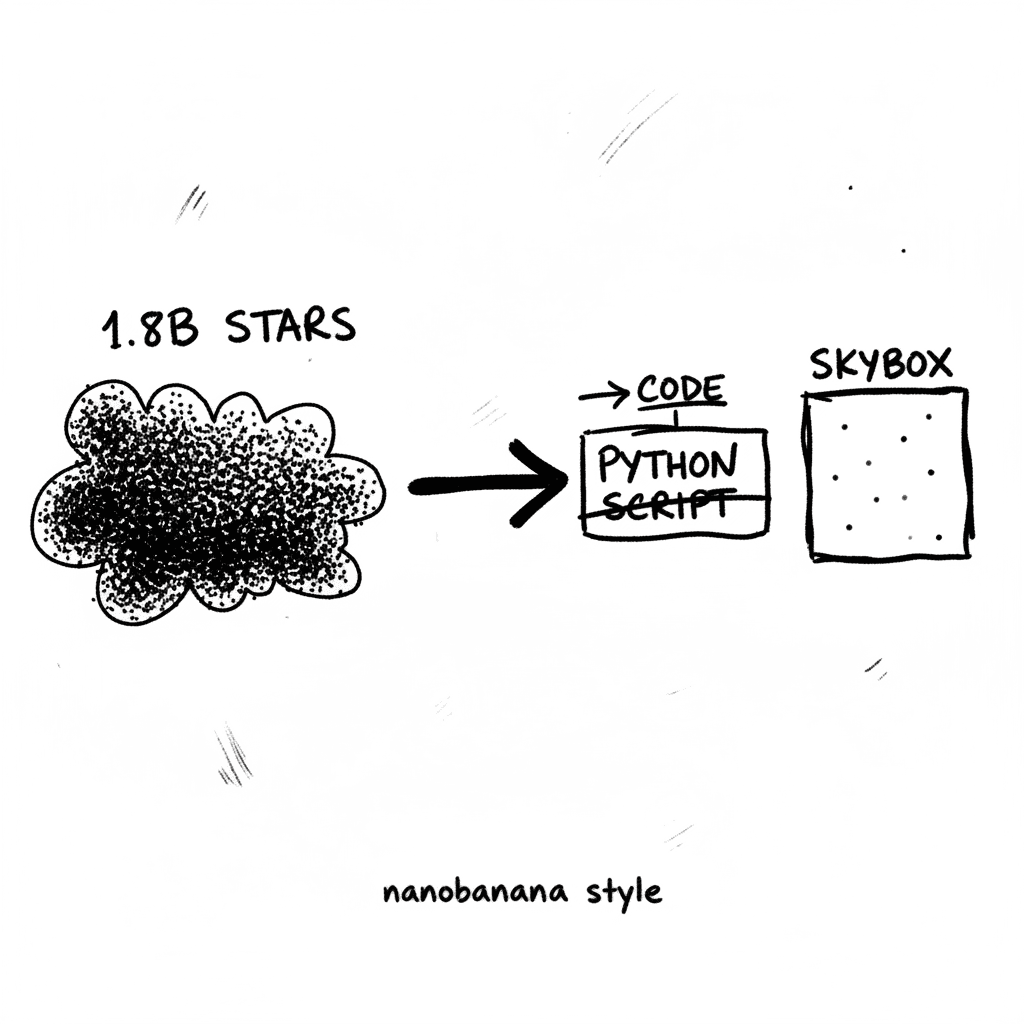
Carta estelar Gaia Mary y el dataset DR3 de la ESA
Gaia Mary es una herramienta de navegación estelar en 3D que recrea la computadora de la nave de "Project Hail Mary" utilizando el dataset real GAIA DR3 de la ESA. Val Hovey ha mapeado más de 1.800 mi
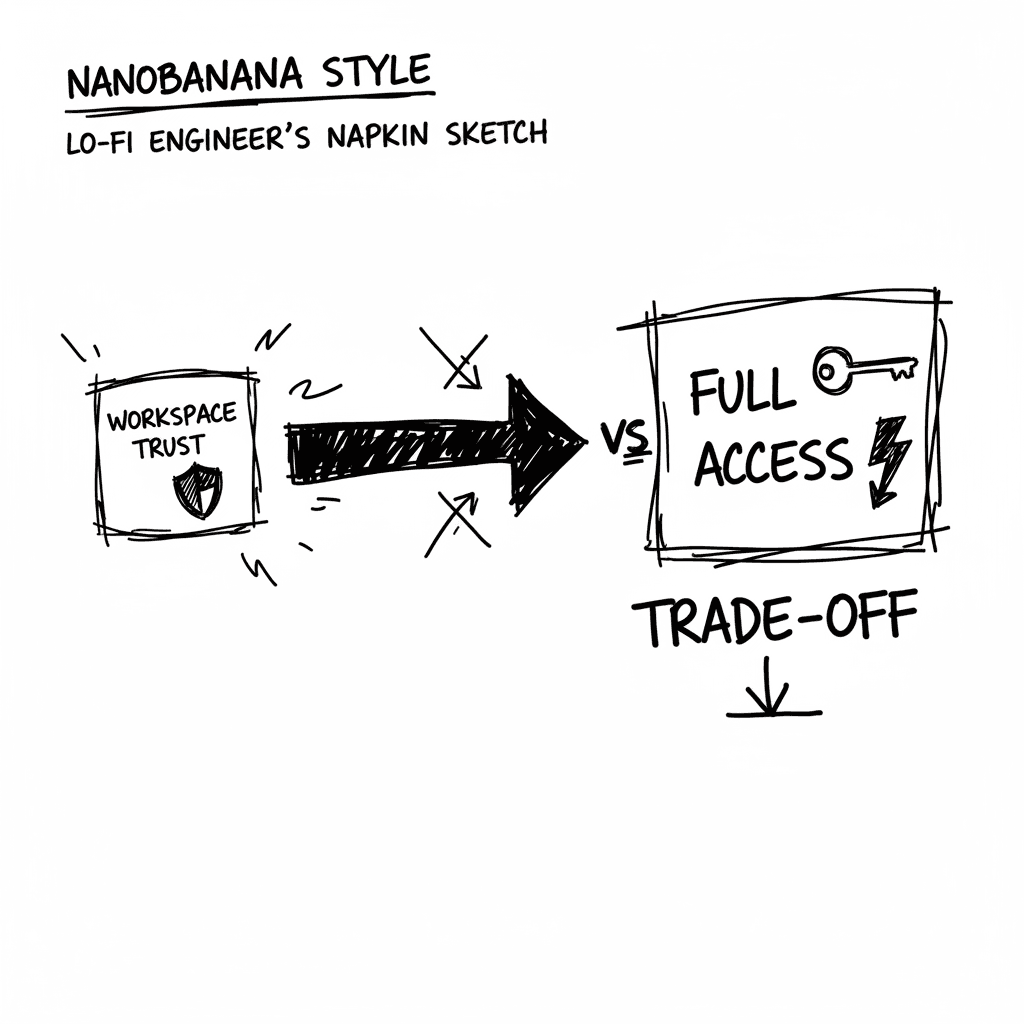
El modelo de seguridad de VS Code falla ante ataques de cadena de suministro
Visual Studio Code utiliza un sistema de "Workspace Trust" y firmas de editores que no impiden que una extensión maliciosa ejecute comandos con privilegios totales de usuario. A pesar de ser el estánd
Mantente al día con las tendencias de adopción de IA
Recibe nuestros últimos informes y análisis en tu correo. Sin spam, solo datos.